はじめに
フロントエンドエンジニアのkhiz125です。最近バックエンドのスキルも深めたいと思っていたところで、ありがたいことにHarperDBのチュートリアル記事を書かせていただく機会をいただきました。本記事はCustom Functionの実装について学習メモです。参考になる方がいらっしゃれば幸いです。
harperDBとは
一言でいうと、「高速で柔軟性のあるデータベースプラットフォーム」です。
公開リリースが2020年とまだ新しく、SQL や NoSQL を独自のデータ モデルに解釈し、どちらの言語からの入力も処理できるそうです。例えば、ユーザーは NoSQL 経由で JSON データを挿入し、結合や CRUD 操作を含む SQL でクエリを実行できます。
日本語の記事はまだ少ないようです。見たところでは、アメリカのデータ連携ベンダーであるCData Software社のホームページに日本語でHarperDBのデータ連携ガイドが書かれていました。Microsoft ExcelやGoogle Sheetsといったものから、BIツールのTableauなど様々な連携が可能なようです。

https://www.cdata.com/jp/kb/tech/harperdb-article-list.rst
Custom Functionとは
公式サイトによると、Custom functionはアクセス可能なエンドポイント、ユーザーの認証と認可の方法、データベースからどのデータにアクセスするか、データをどのように集約してユーザーに返すかを完全に制御できるとのこと。後述しますが、admin画面上でRoutesやHelper functionを定義できるので、クライアント側からは設定したエンドポイントにアクセスしてパラメータを渡すことでサーバーサイドの役割を代替できる、というようなイメージでしょうか。AWSでいうところのAWS Lambdaと同様の機能だと思います。
例えばNode.jsのWeb アプリケーション・フレームワークであるExpress.jsでサーバーを構築してルーティングを作成するという作業をHarperDBのCustom functionで実装します。言い換えれば、私のようなフロントエンドのエンジニアからみると、Node.jsでサーバー立ち上げて、エンドポイント作成して…という作業を直接HarperDBに書き込めるという感じです。データベース内で高度な計算やデータの変換を行うことができるので、ネットワークのレイテンシやクライアントの処理能力に依存せずに高度な処理を実現できるというメリットなどがあるとのことです。

それではHarperDB Cloudのアカウント作成からインスタンスのセットアップを通じて、Custom Functionの使い方についてみていきたいと思います。
アカウントの作成
まずはアカウント作成です。一連の流れは公式のYoutubeチャンネルに動画があります。解説は英語なので、英語がわかる方は動画がわかりやすいと思います。
公式ページにアクセスしてアカウントを作成しましょう。公式サイトはこちら。
Start Freeというボタンをクリックします。
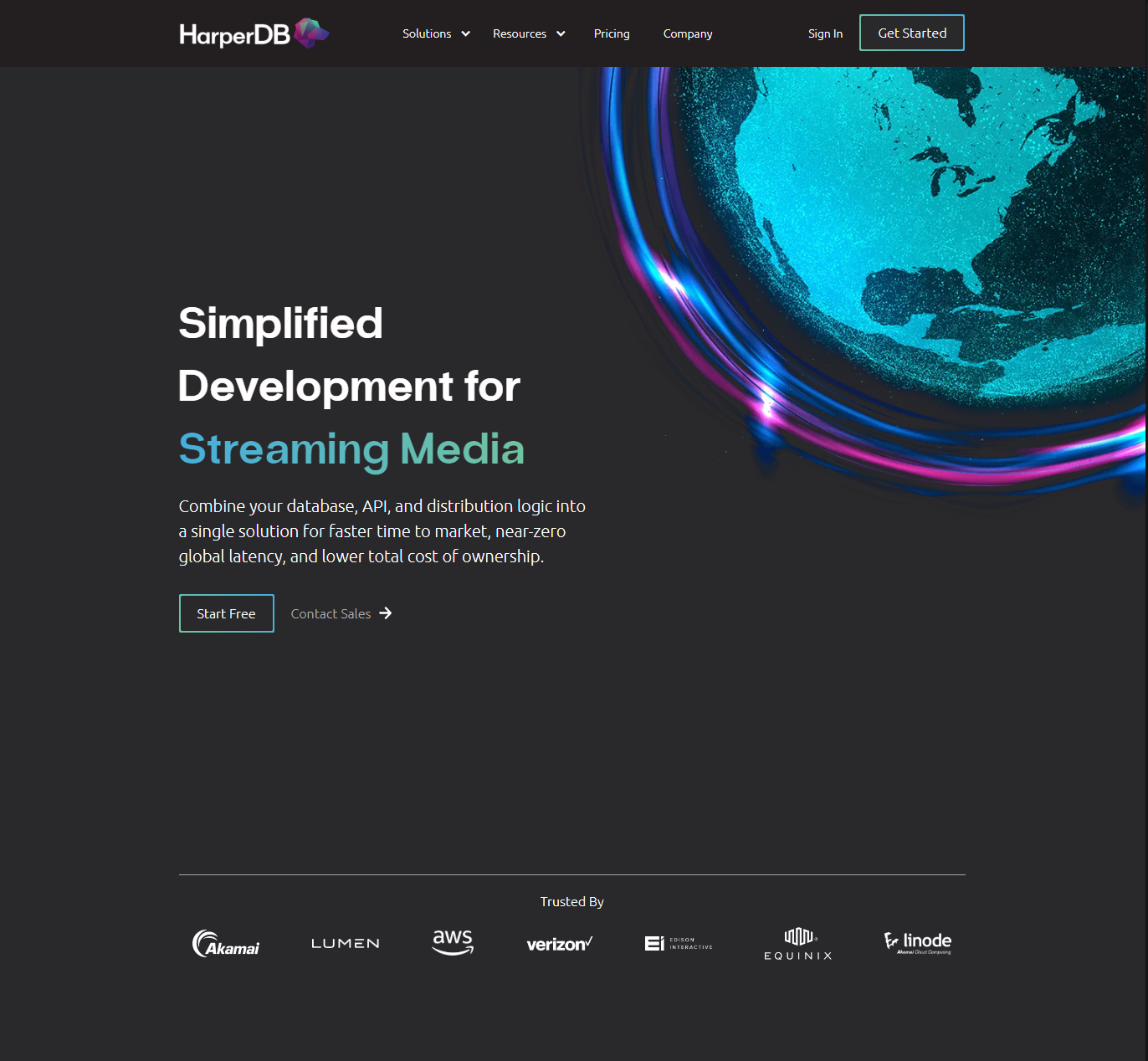
サインアップページに移るので、ここで必要な情報を書き込みます。4番目の入力箇所はHTTPリクエストを送信するHarperDB Cloud InstancesのURLのドメイン名の一部になります。入力を終えたらSign up for freeをクリックします。
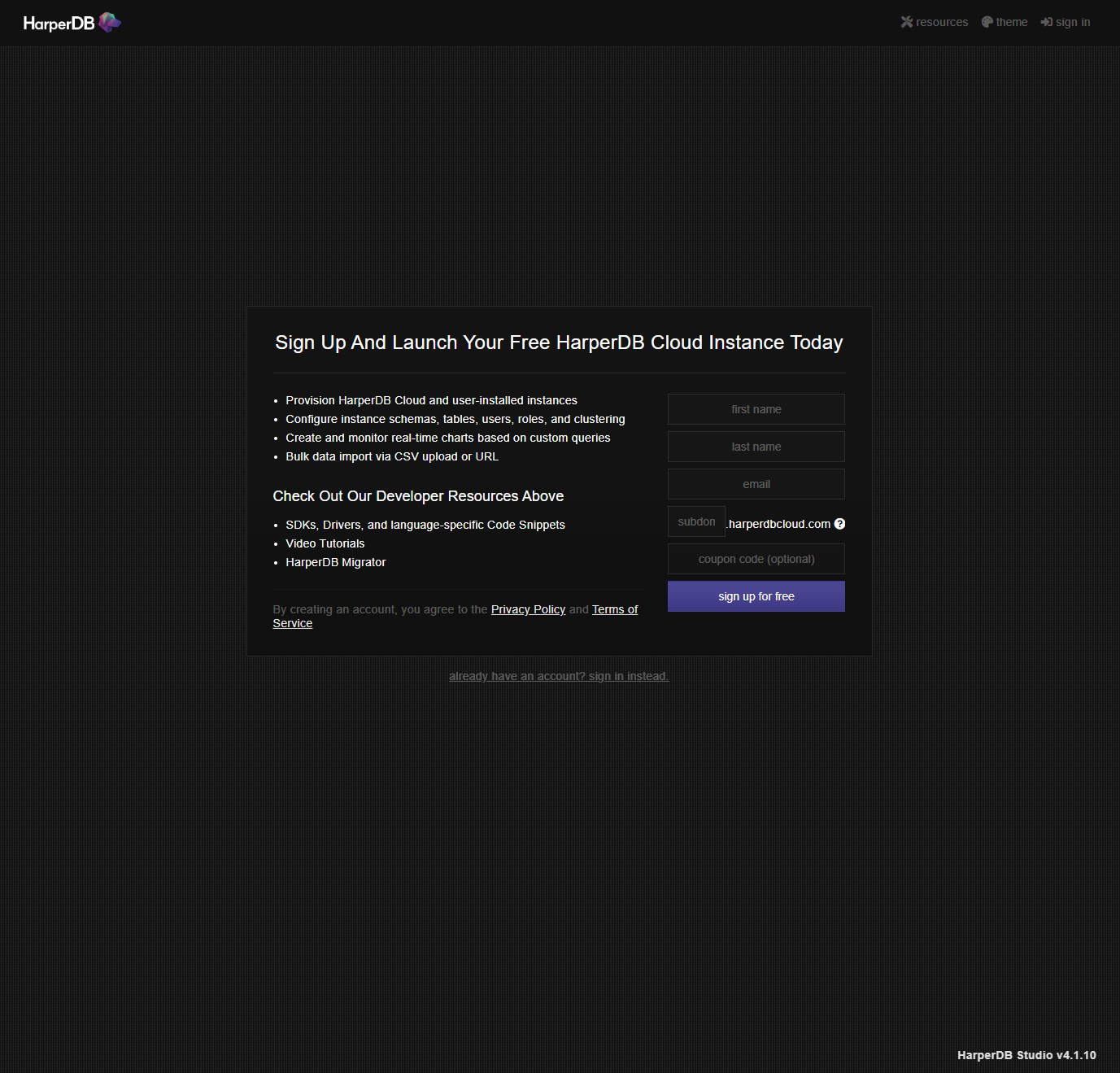
インスタンスの作成
アカウントの作成が完了するとAdminページに移ります。Create New HarperDB Cloud Instanceをクリックします。
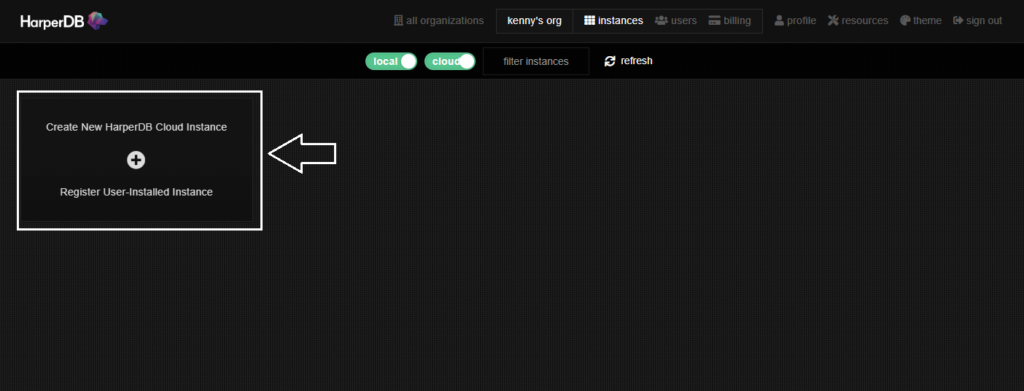
Instance Typeで左側のCreate AWS or Verizon Wavelength Instanceを選択します。
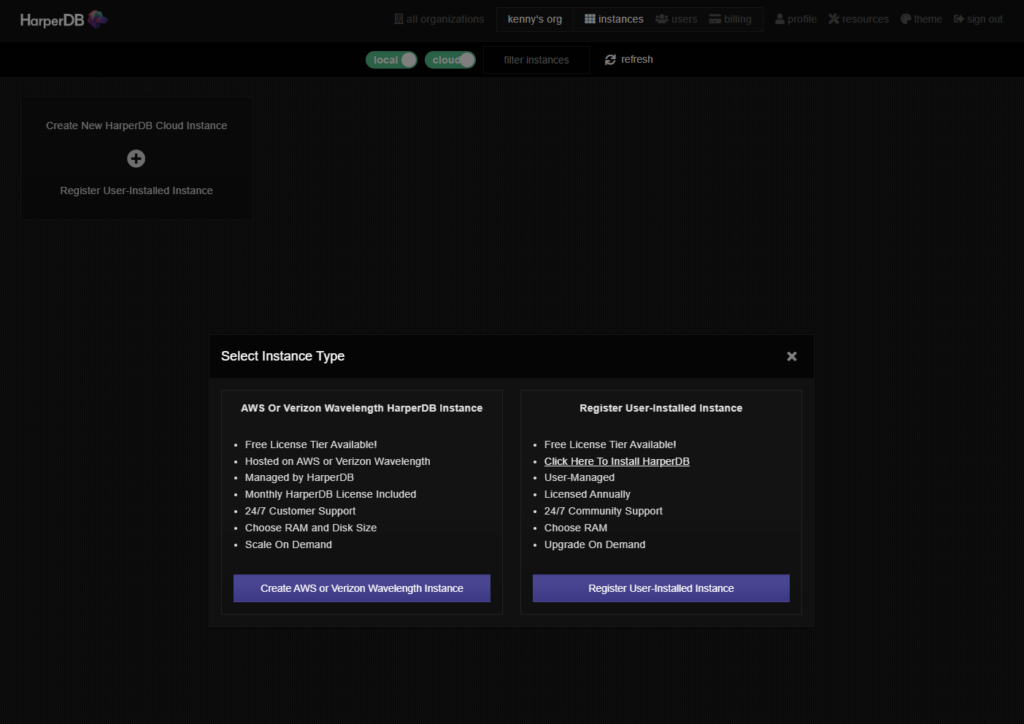
プロバイダーは左側のCloud on AWSを選択し、Instance Infoをクリックします。
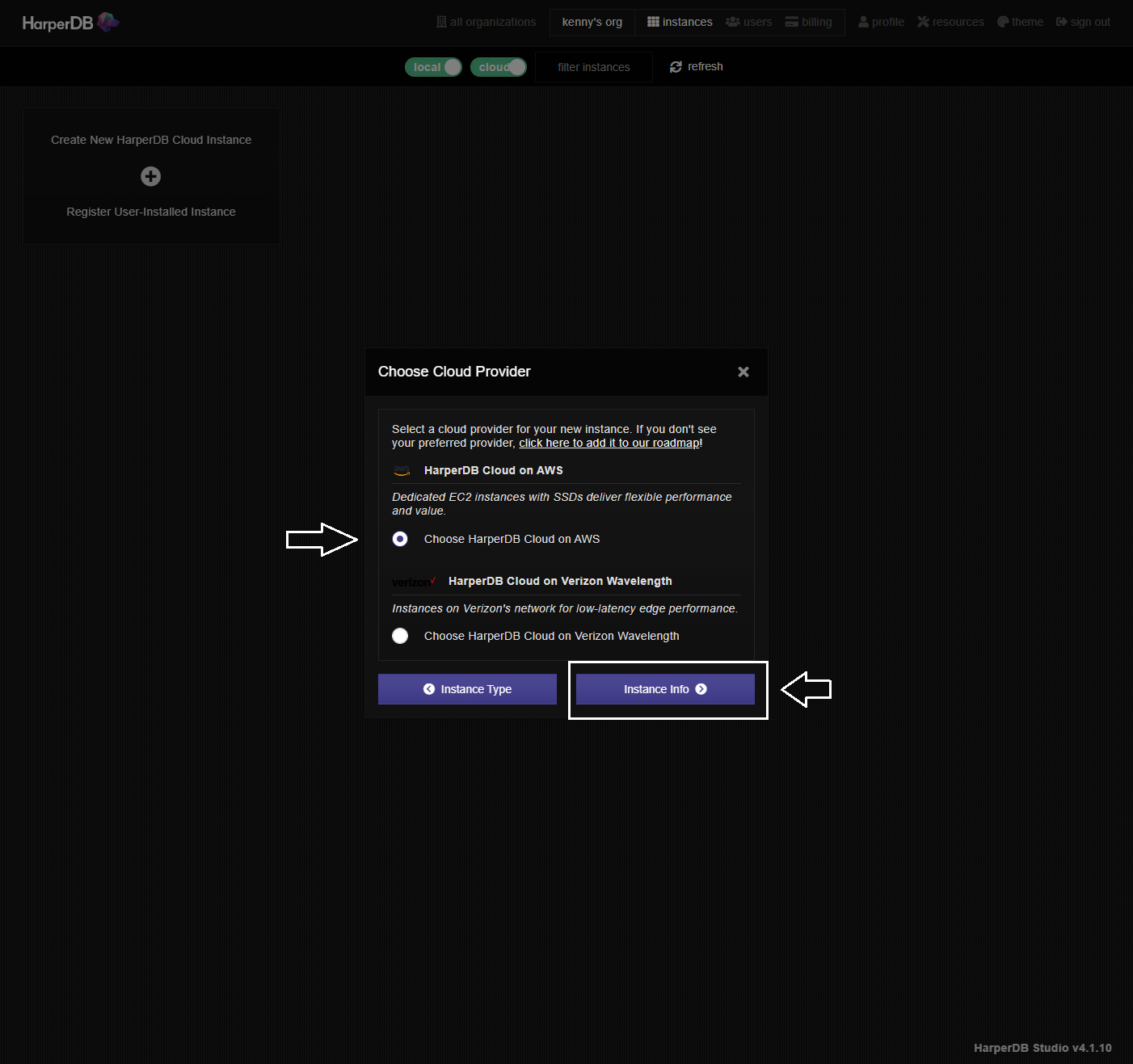
Instance NameとUsernameを入力します。Instance NameはURLのドメイン名の一部になります。
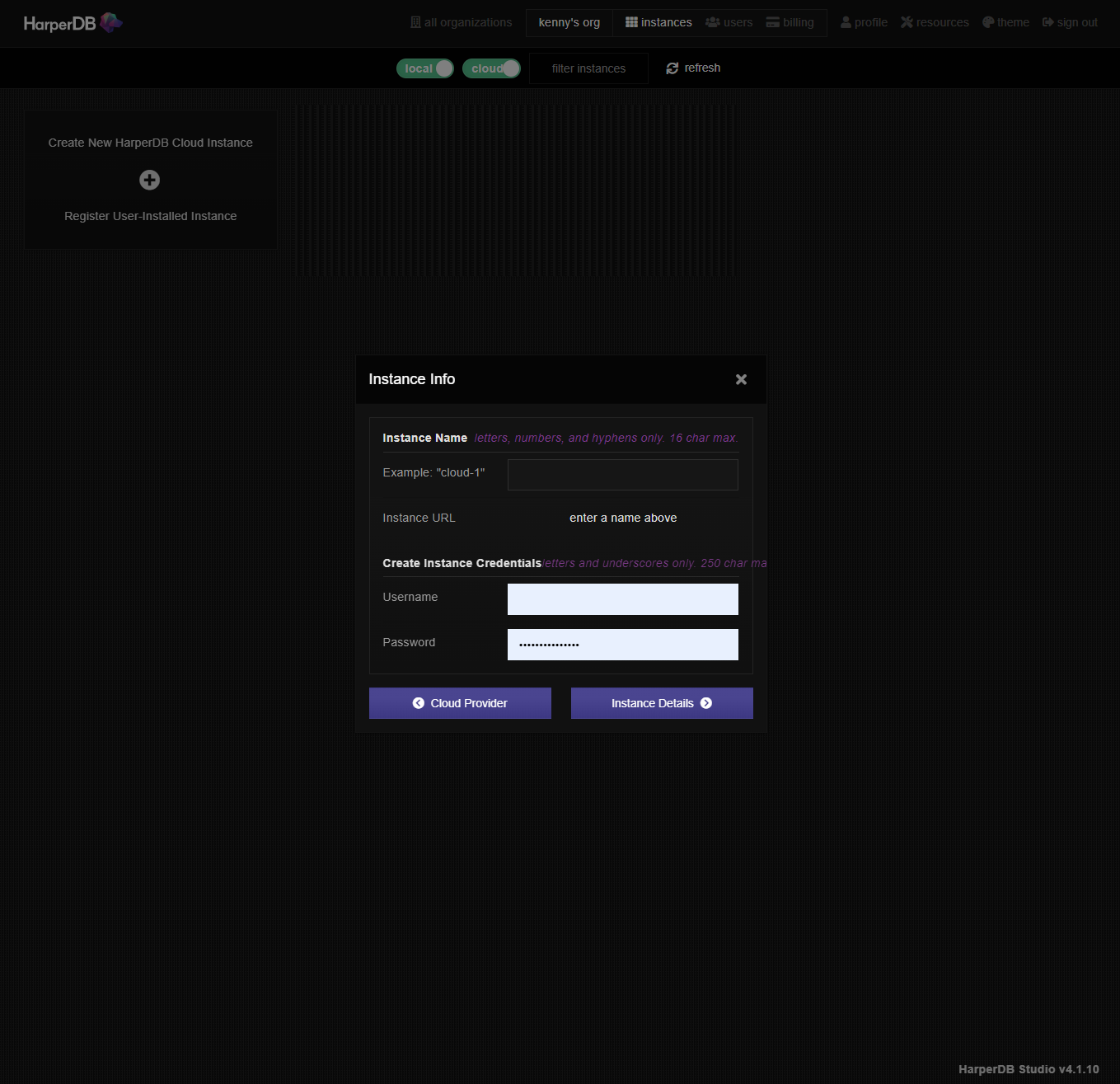
スペックを選択します。RAM、Storage Sizeとも無料枠があるのでこちらを選択します。日本在住であればリージョンはUS WESTでよいでしょう。Confirm Instance Detailsをクリックします。
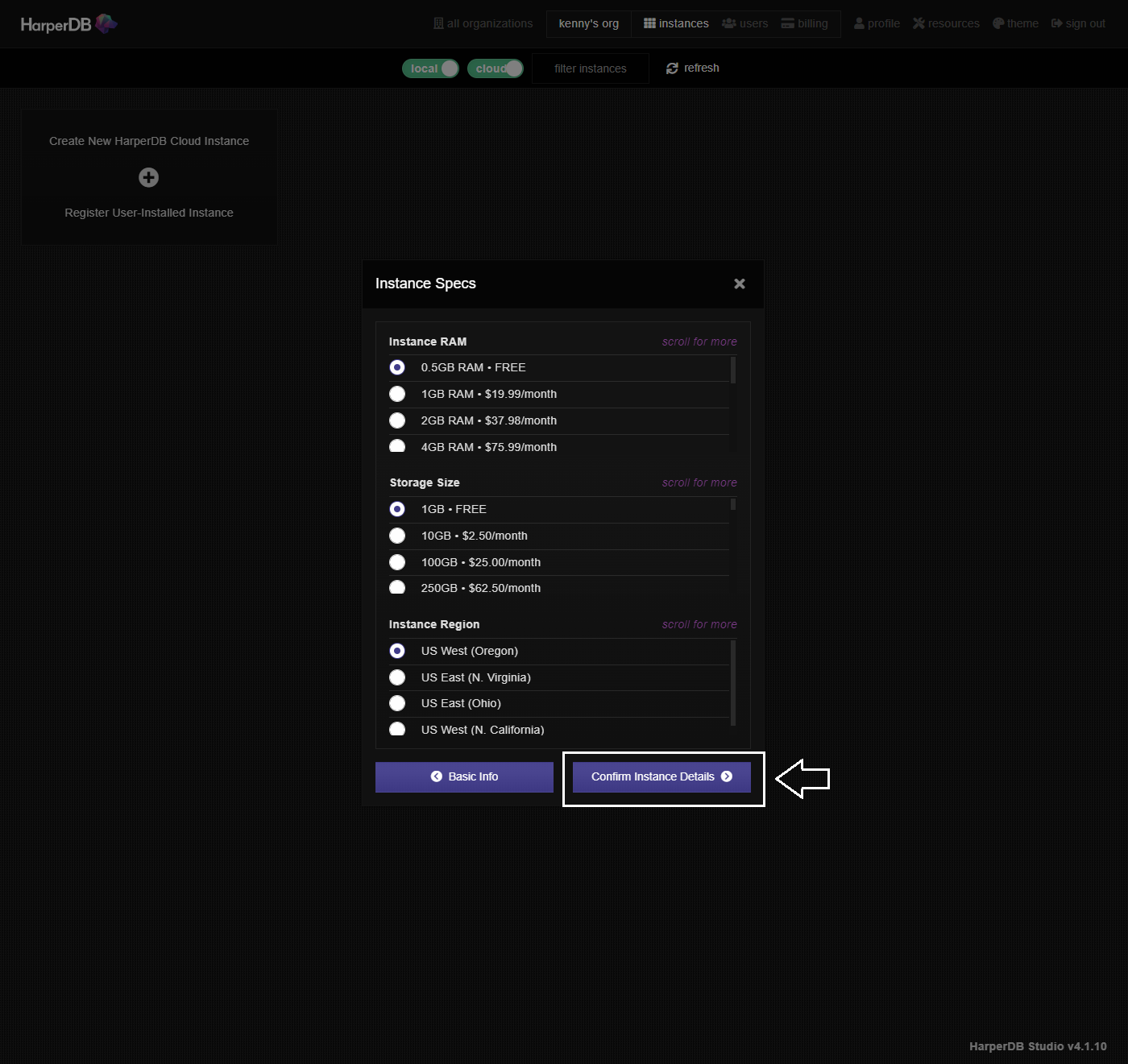
入力内容に問題がなければAdd Instanceボタンをクリックします。するとローディングが始まります。インスタンスが作成されるまで数分かかります。
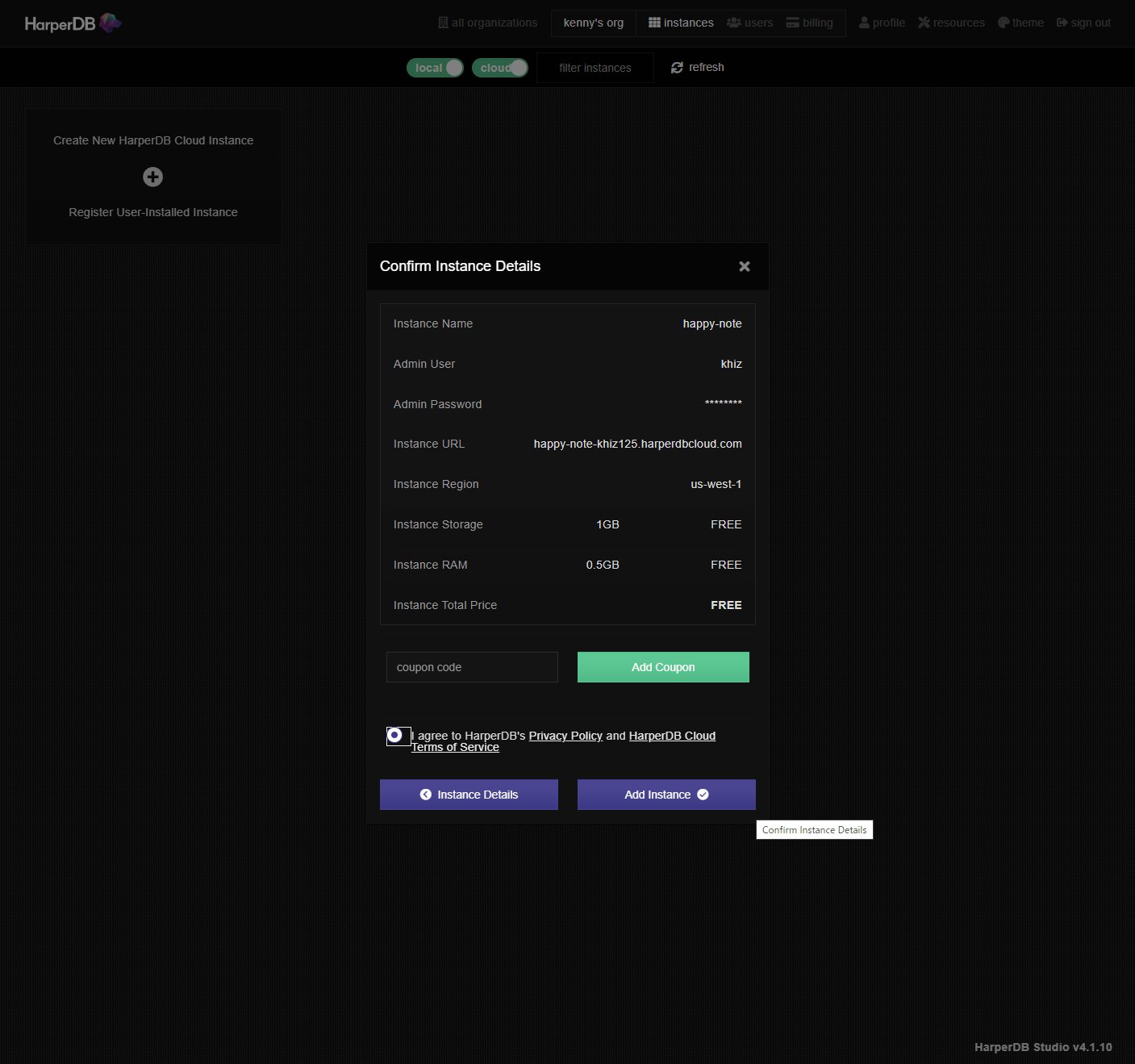
インスタンスの作成が完了すると下のようにSTATUSにOKが表示されます。無料アカウントで作成できるインスタンスは1つとなります。次はschemasとtableの作成です。作成したインスタンスをクリックします。
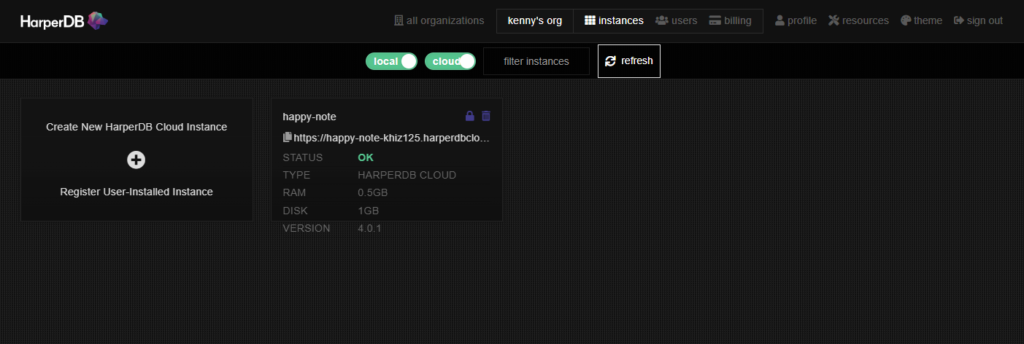
schemasとtableの作成
インスタンスをクリックすると下のような画面が表示されます。ここでschemasの欄に任意の名称(プロジェクト名など)を入力して緑色のチェックボタンをクリックします。
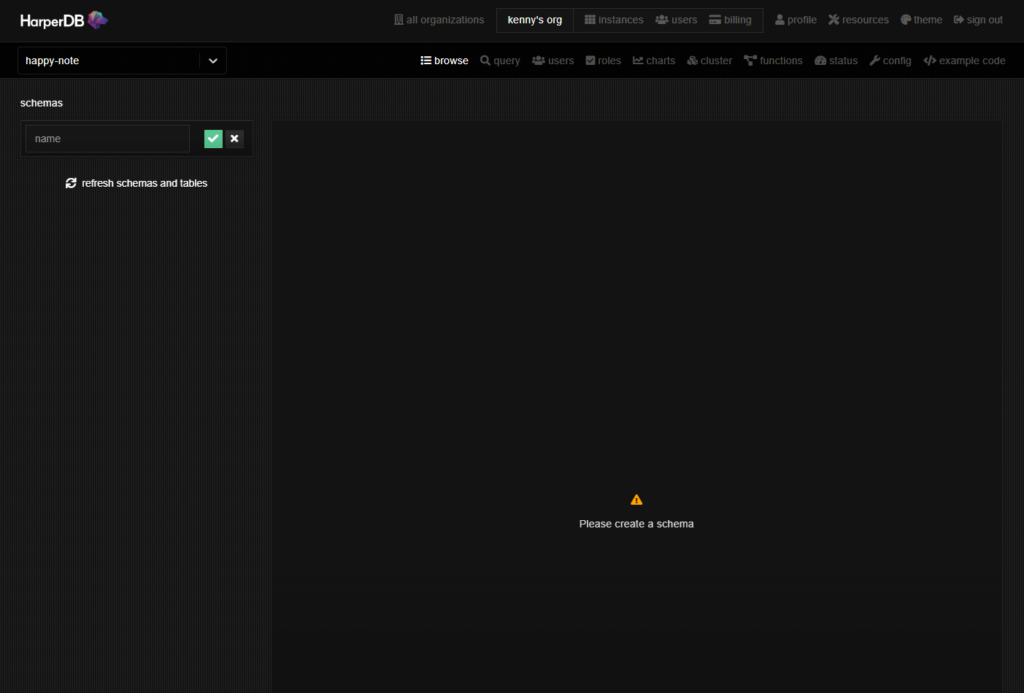
schemasを入力するとtablesの欄が表示されます。tableの名称を入力し、となりのhash attr.にはidと入力して緑色のチェックボタンをクリックします。
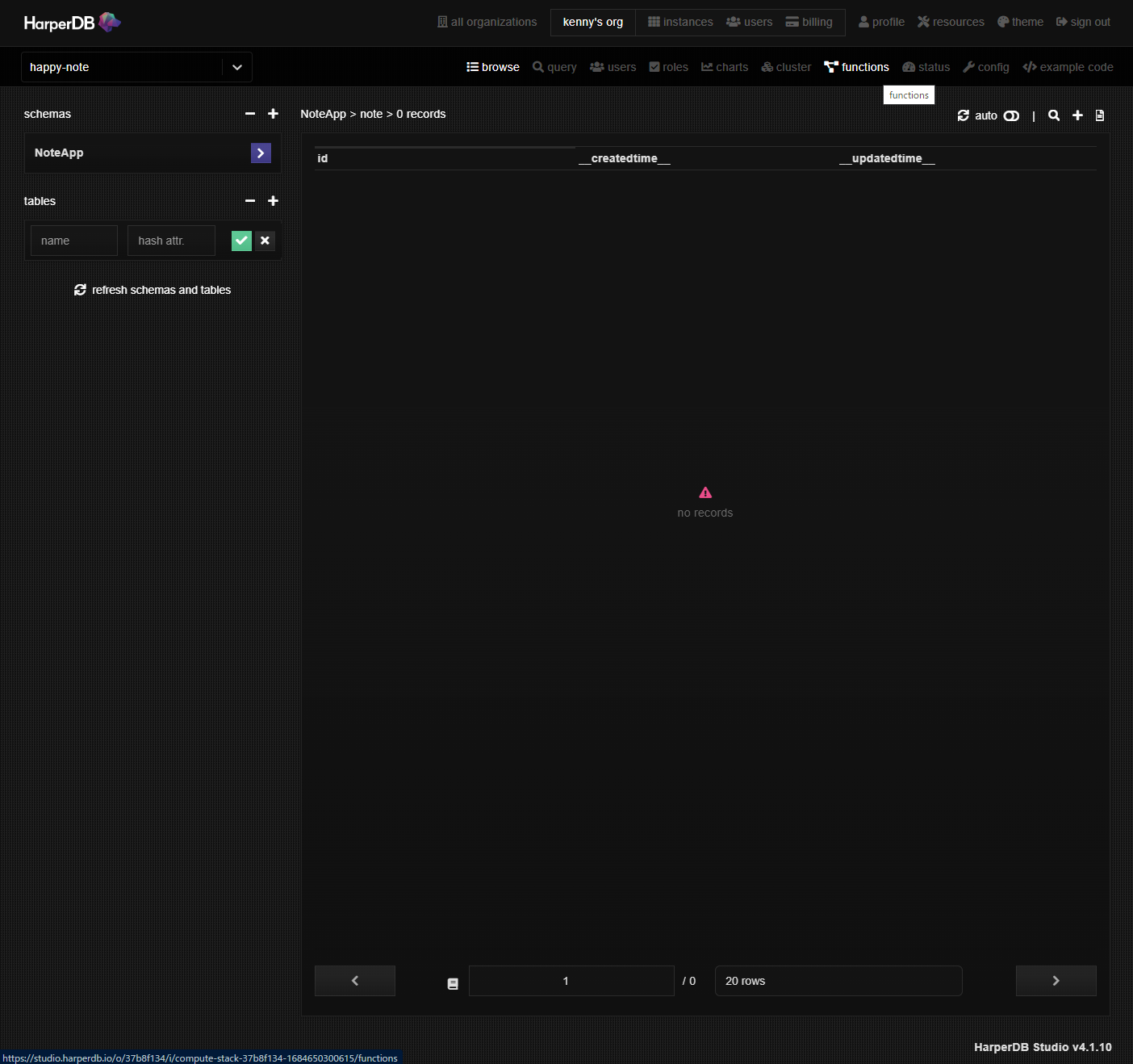
入力が完了すると空のテーブルが表示されます。
画面右上に表示されているディスクカードをクリックすることでcsvファイルから予め作成したデータテーブルの一覧を入力することもできます。
HarperDBは動的スキーマ(Dynamic Schema)をサポートしており、新しいデータの挿入や更新時のデータ追加などで新しいカラムが作成されますので、カラム作成などの細かい作業は不要です。
Custom funtionの設定
それではCustom Functionの設定に入ります。まずはテスト用のエンドポイントを作成してapiが機能するところを見ていきたいと思います。
ヘッダーにあるfunctionsをクリックします。
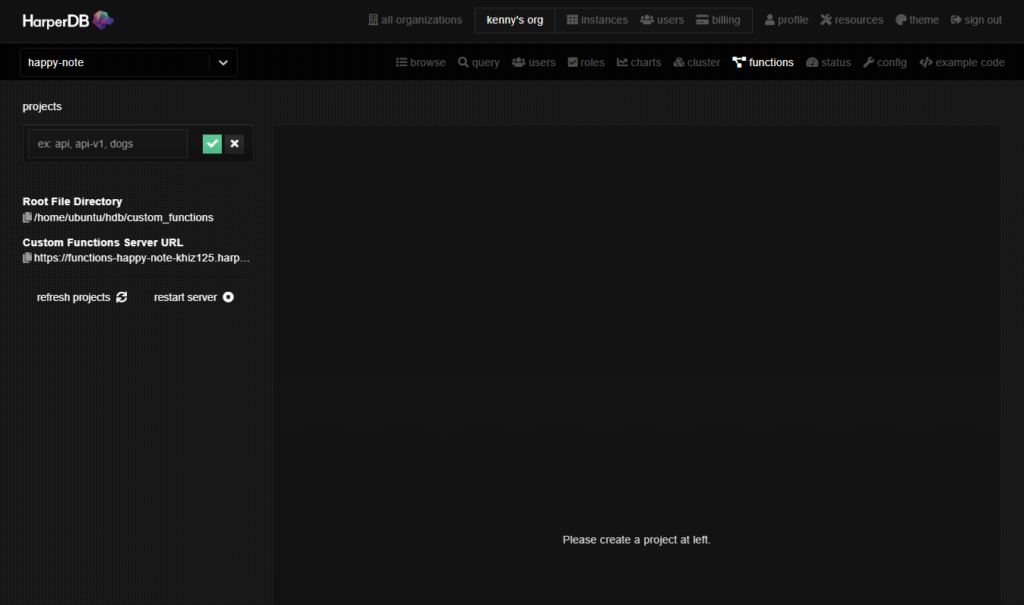
はじめに、projectsを作成します。空欄に入力した名称がスキーマ名になります。緑のチェックマークをクリックすると、
- `/schema_name/rountes`
- `/schema_name/helpers`
が生成され、それぞれのコード例が表示されます。
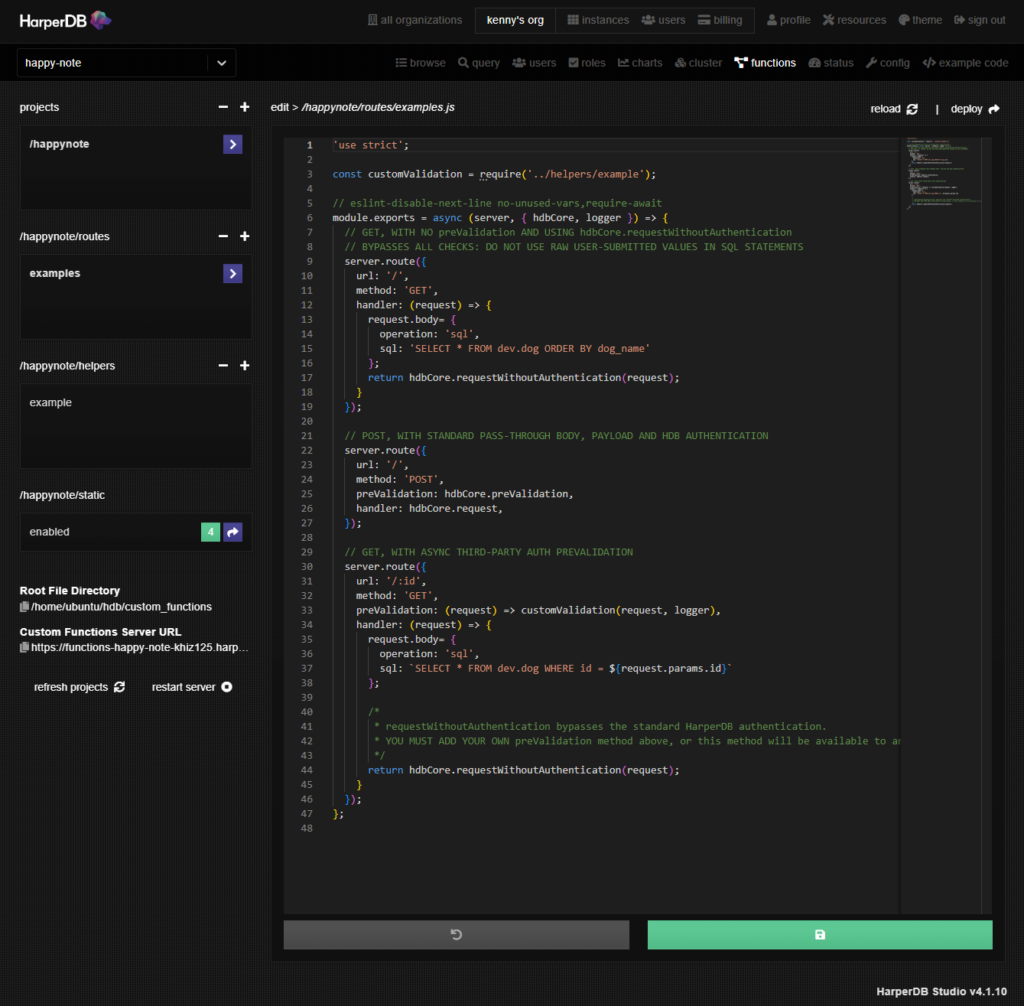
テスト用のエンドポイントを作成します。/schema_name/rountesの右にあるプラスボタンをクリックし、任意の名称を入力します。この名称がテーブル名になります。緑のチェックマークをクリックすると、Custom Functionの編集が可能となります。
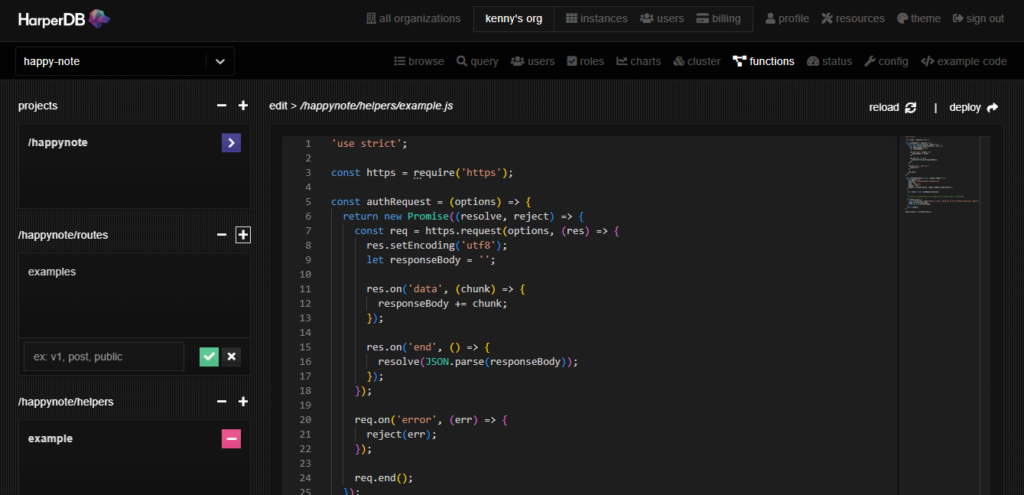
それではテスト用のコードを入力します。ひな形として記載されているコードで不要な箇所を削除し、下記のように入力します。server.routeの引数をオブジェクトにして、
- urlは先ほど入力したテーブル名を入力します。テーブル以下は任意のエンドポイントです(画像では/list)。
- methodにCRUDを設定します。
- handler以下に任意の関数を設定します。データベース内にあるデータをGETしたり、あるいは特定のデータのみ抽出するために、抽出用のエンドポイントを別途作成して、filterをかけてGETするといったようなことが可能です。
画面上の下部にある緑色のディスクマークをクリックして保存します。保存が完了したら右上のdeployをクリックします。
'use strict';
module.exports = async (server, { hdbCore, logger }) => {
server.route({
url: '/notes/list',
method: 'GET',
handler: () => {
return "My Happy notes here";
}
})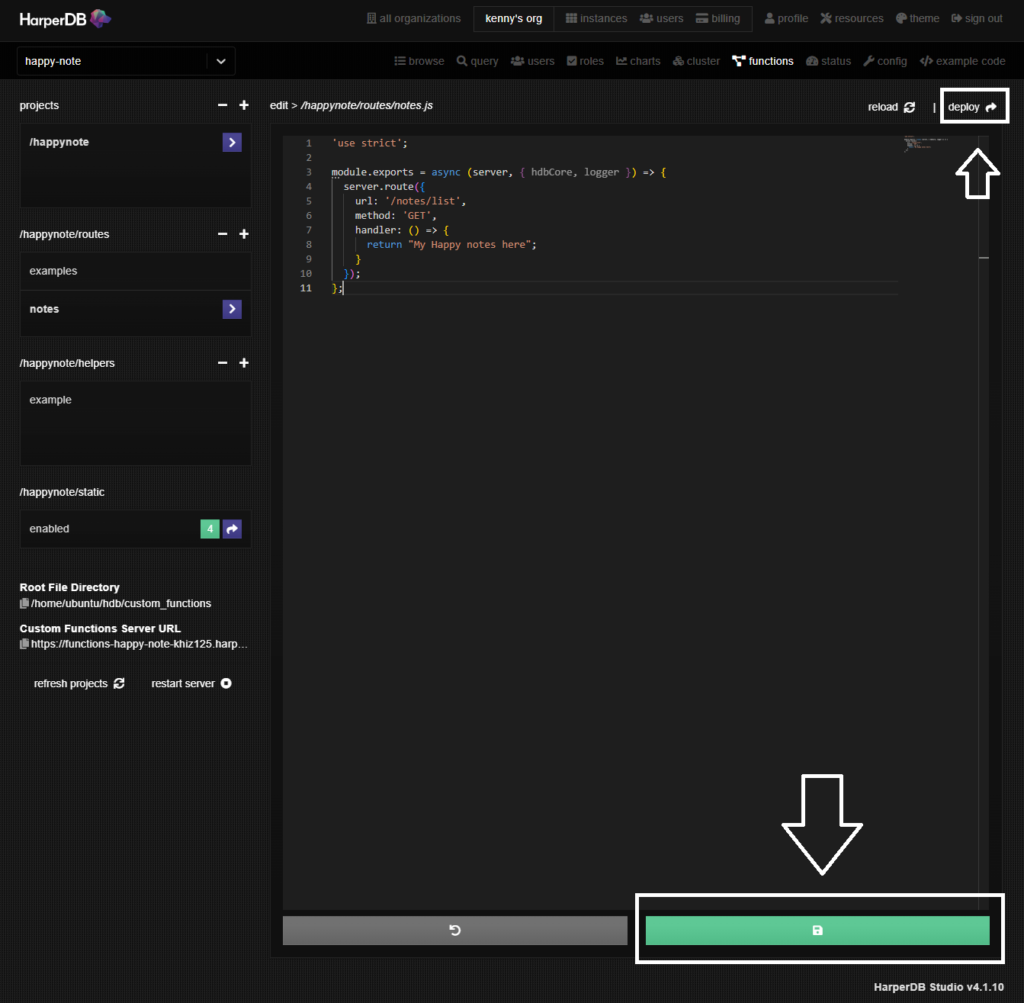
デプロイされますので、左側にあるCustom Functions Server URLの左にあるペーパーアイコンをクリックしてURLをコピーします。
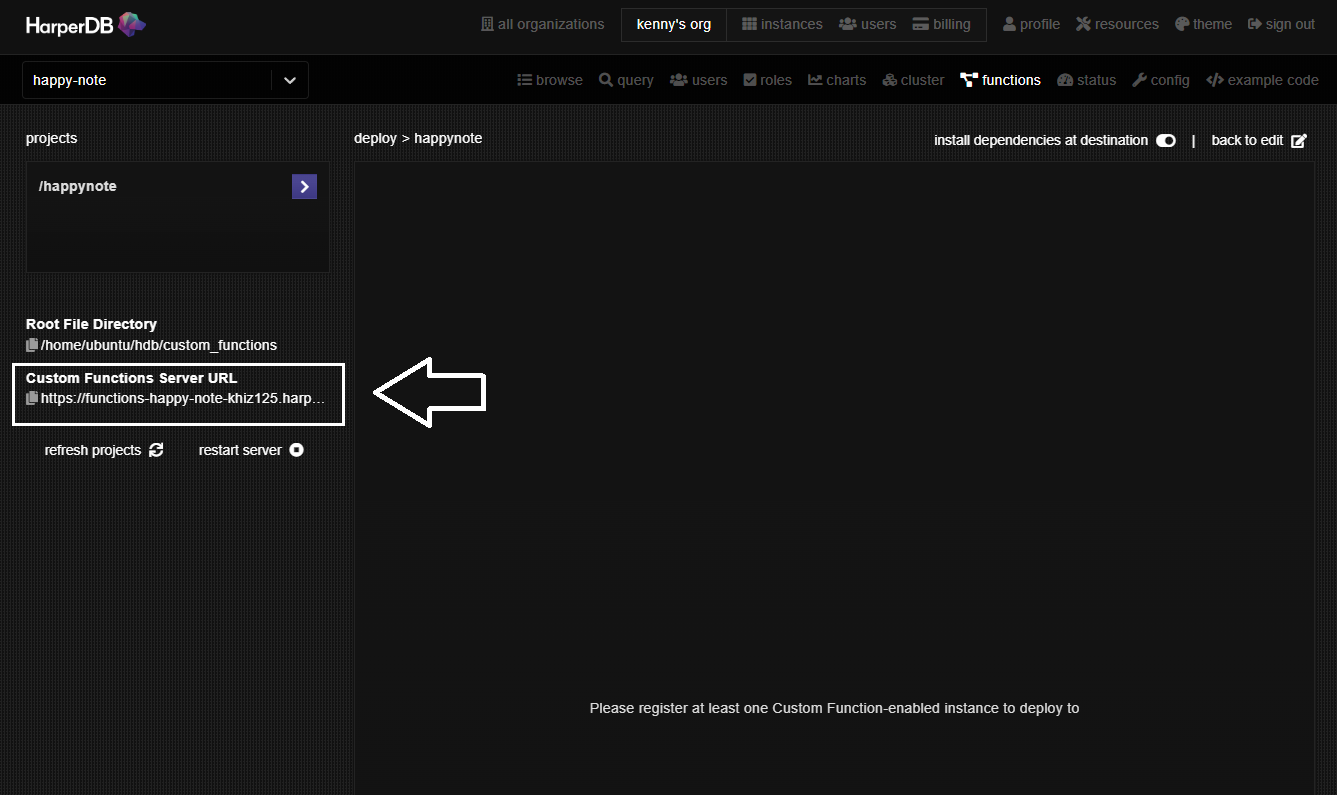
コピーしたURLをブラウザのアドレスバーに貼り付けて、最後尾に先ほど入力した/project_name/rountes/endpointを追加してみましょう。
handlerメソッドで入力した内容が表示されていればCustom Functionがデプロイされていることが確認できます。

CRUD API
それではCRUDを実装していきます。まずはGETから。
- GET
'use strict';
module.exports = async (server, { hdbCore, logger }) => {
server.route({
url: '/notes/list',
method: 'GET',
preParsing: (request, response, payload, done) => {
request.body = {
operation: 'sql',
sql: 'SELECT * FROM happynote.notes'
};
done();
},
preValidation: hdbCore.preValidation,
handler: hdbCore.request
});Fastify 風の Hooks、preParsing、preValidationが定義されています。
preParsingでpreValidation、handlerの前にリクエストのbodyを定義します。operationをsqlとし、sqlでSQL文を定義します。定義後にdone()メソッドを呼ぶことで、以下のpreValidationへと進みます。hdbCore.preValidationはHarperDBのデフォルトのリクエスト認証です。認証キーはheaderのconfig画面から取得できます。Basicの左のアイコンをクリックすることで認証キーをコピーできます。
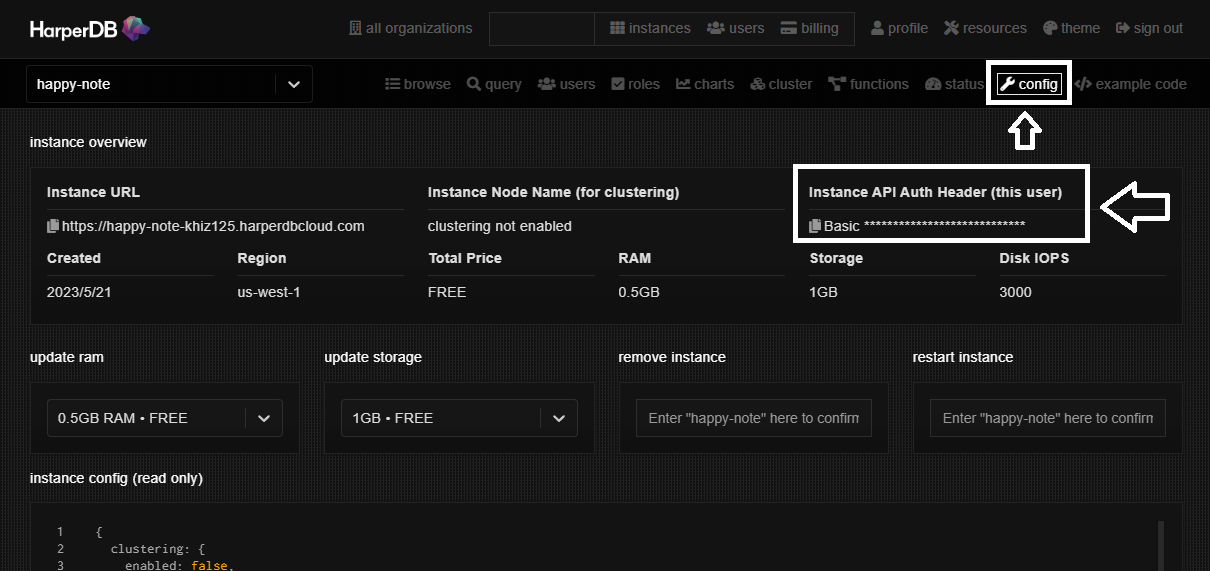
フロントエンド側は.envを利用して次のように定義しました。
utils.ts
import axios, { AxiosInstance, AxiosRequestConfig, AxiosResponse } from "axios";
const BaseUrl = `${process.env.REACT_APP_HARPERDB_CUSTOM_FUNCTIONS_URL}`;
const api: AxiosInstance = axios.create({
baseURL: BaseUrl,
});
const setupConfig = (config: AxiosRequestConfig): AxiosRequestConfig => {
return {
headers: {
Authorization: `Basic ${process.env.REACT_APP_HARPERDB_API_KEY}`,
},
...config,
};
};
export const get = (
url: string,
config: AxiosRequestConfig = {}
): Promise<AxiosResponse<any, any>> => {
return api.get(url, setupConfig(config));
}
.env.local
REACT_APP_HARPERDB_CUSTOM_FUNCTIONS_URL="https://○○○○.harperdbcloud.com"
REACT_APP_HARPERDB_API_KEY="○○○○"
- POST
POSTは次のように定義します。
server.route({
url: '/notes/add',
method: 'POST',
preValidation: (request, response, done) => {
request.body = {
operation: 'insert',
schema: 'happynote',
table: 'notes',
records: [request.body]
};
done();
},
handler: hdbCore.request,
});preValidationでrequest.bodyを定義します。
- operationをinsert
- schemaをスキーマ名
- tableをテーブル名
- recordsはブラケットでかこってrequest.bodyとします。フロントエンド側から次のようなJSON形式で渡すと、合致しているカラムに入力されます。
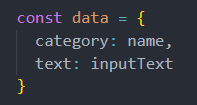
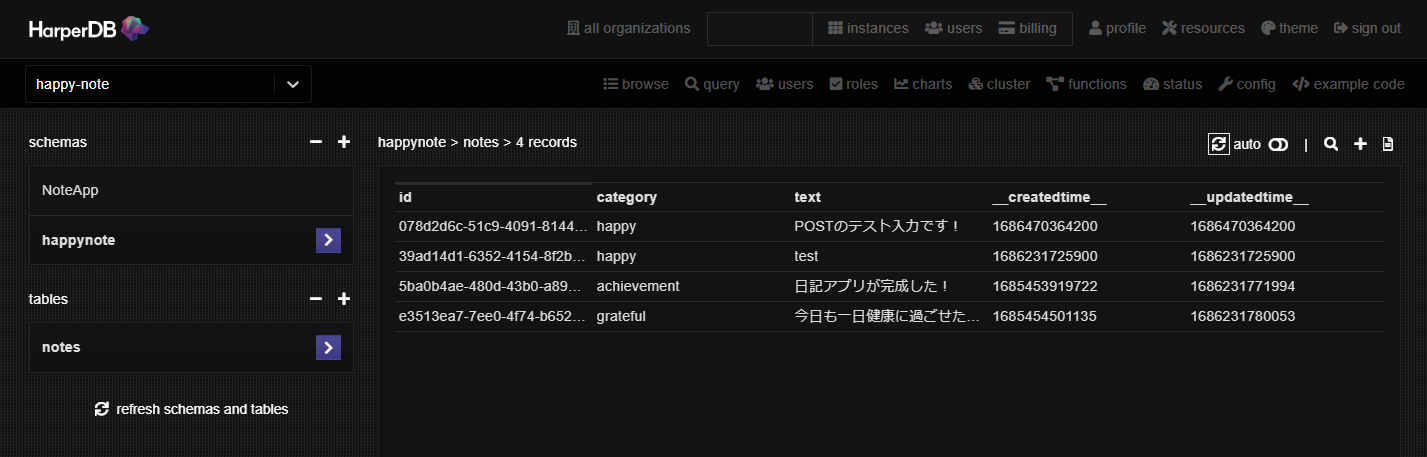
動的なのでテーブルのカラムに同じ名称がなければ自動的に作成されます。
- PUT
PUTは次のように定義します。
server.route({
url: '/notes/update',
method: 'PUT',
preValidation: (request, response, done) => {
request.body = {
operation: 'update',
schema: 'happynote',
table: 'notes',
records: [request.body]
};
done();
},
handler: hdbCore.request,
});operationをupdateとする以外はPOSTとほぼ同じです。
- DELETE
DELETEは次のように定義します。
server.route({
url: '/notes/remove/:id',
method: 'DELETE',
preValidation: (request, response, done) => {
request.body = {
operation: 'delete',
schema: 'happynote',
table: 'notes',
hash_values: [request.params.id]
};
done();
},
handler: hdbCore.request,
});POSTやPUTとほぼ同じです。operationをdeleteとし、hash_valuesにidを渡します。定義が終えたら再度保存し、deployボタンをクリックしてデプロイを完了しましょう。
フロントエンド側は次のような感じです。

Custom function実装で作ったアプリ
Webアプリは日記帳みたいなものを作りました。
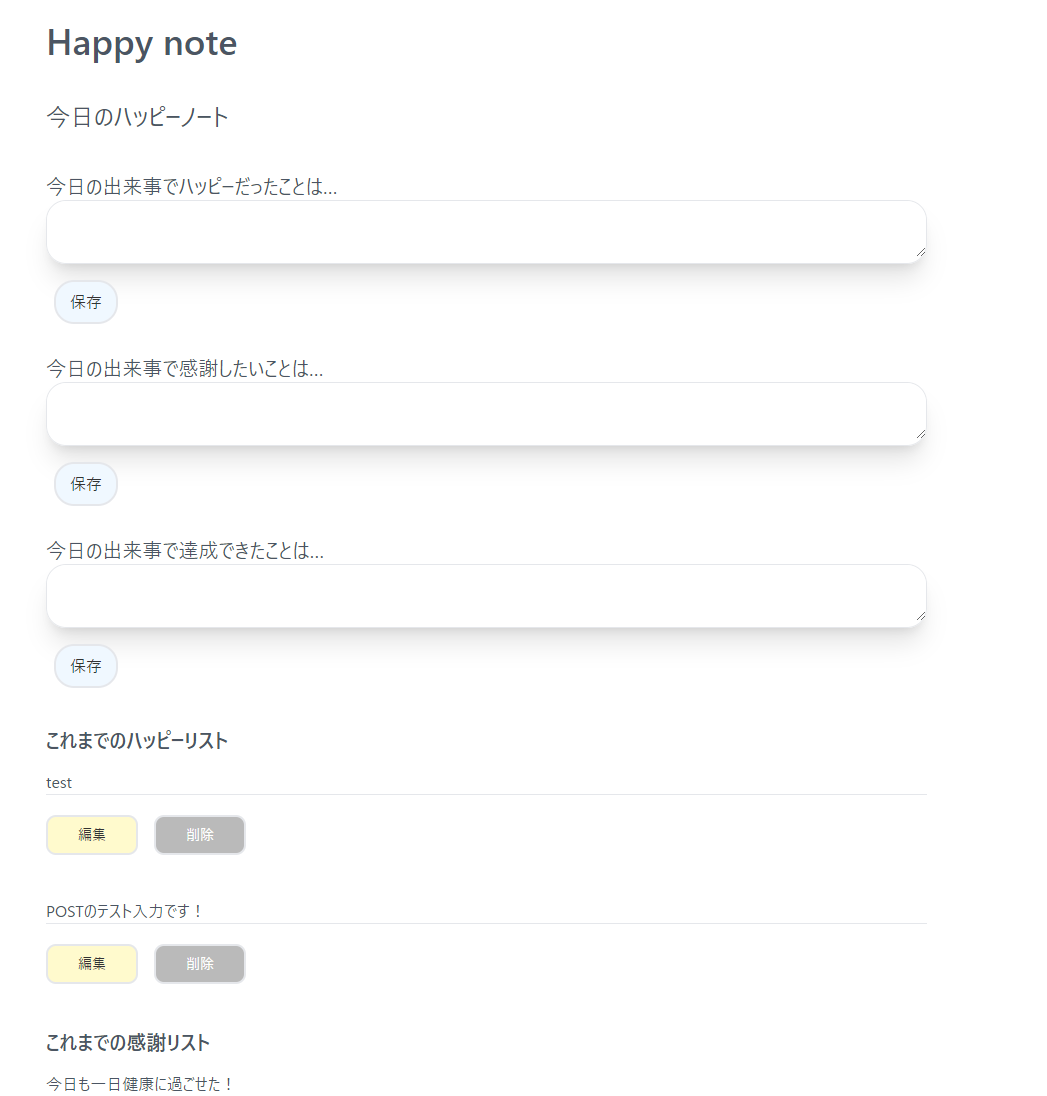
デザインセンスなさ過ぎて申し訳ないですが、ご参考までにrepositoryを置いておきます。
⇒ https://github.com/khiz125/happy-note-frontend/tree/main
備考
最後に、HarperDBの特徴についてです。HACKERNOONの記事に書かれているいくつかの内容や、公式サイトのブログなどで書かれていることを箇条書きで記載します。
- HarperDB は、SQL と NoSQL の分散型データベースおよび開発プラットフォーム
- 高速なメモリ マップ型のキーと値のストアである LMDB の上に構築されている
- 1 秒あたり 20,000 回の書き込みと 120,000 回の読み取りを処理
- Fastify を利用した統合 API サーバー
- データベースのスキーマレスな設計と柔軟なデータモデルにより、アプリケーションの変更や拡張が容易
- 機械学習モデルのトレーニングとデプロイメントにも活用
- エッジデバイス上でのデータ処理と分析を高速化し、レイテンシとコストを削減
以上となります。最後までご覧いただきありがとうございます。参考になりましたら幸いです。
